This is part of a 3 part series!
Part one: General concepts: https://www.vicharkness.co.uk/2019/01/20/the-art-of-defeating-facial-detection-systems-part-one/
Part two: Adversarial examples: https://www.vicharkness.co.uk/2019/01/27/the-art-of-defeating-facial-detection-systems-part-two-adversarial-examples/
Part three: The art community’s efforts: https://www.vicharkness.co.uk/2019/02/01/the-art-of-defeating-facial-detection-systems-part-two-the-art-communitys-efforts/
This article makes up the second part of my discussion of the art community’s efforts to defeat facial detection/recognition techniques. Although the aim of this series is to discuss non-technical methods, I feel like I really should mention adversarial examples.
What are adversarial examples?
Adversarial examples are pieces of data (in our case, images) which have been deliberately crafted to cause a system to misclassify them. They can be targeted towards a specific misclassification (e.g. having a cat be classified as a table), or they can be generic misclassifications (e.g. a dog no longer appears to be a dog). These attacks are specially crafted to target neural network systems, although models trained on a given neural network may be useable on another.
Adversarial examples are crafted through taking advantage of how a neural network based image classifier classifies an image. Say you had a picture of a dog. The image is 255×255 pixels in size, and each pixel has an RGB (red green blue) value associated with it which describes what colour it is. This array of pixels is fed in to a neural network, which does some fancy mathematics (which we won’t get in to here) on it. It then outputs a classification (or range of classifications), alongside confidence values of 0 to 1. The picture of the dog could result in classifications of “Dog: 0.95”, “Cat: 0.6”, “Fox: 0.2”, etc. The results may not always be so clear cut. You could have an image that seems to classify as nothing in particular (e.g. a whole host of classifications around 0.01), or of course incorrect classifications. No system is perfect. Quite often, images are referred to based on their highest classification, even if the number is still very small.
When doing maths you write start with a bunch of numbers, perform some operations, and receive a result. If you start with the result you can work backwards and get back the original numbers. This principle is used to create adversarial examples. You start out with your confidence value of “Chair: 1.0” and use a technique known as backpropagation (various algorithms for this are available online) to compute backwards through the neural network to get the initial input pixel values that correspond with that result. In our case, a 255×255 array of pixels that each has an associated RGB value. These generally look nothing like the target function to the human eye, but they are what the neural networks “considers” the concept to look like. These pixel arrays can then be numerically added or subtracted from an image array, causing the image to look more or less like the subject that the back propagation was developed from. Sometimes they can cause the image to be classified as something else entirely. Pixel arrays generated by backpropagation are generally quite faint, and so often have to be magnified (e.g. all values multiplied by 100) to be discernible to the human eye.
An example can be seen here:
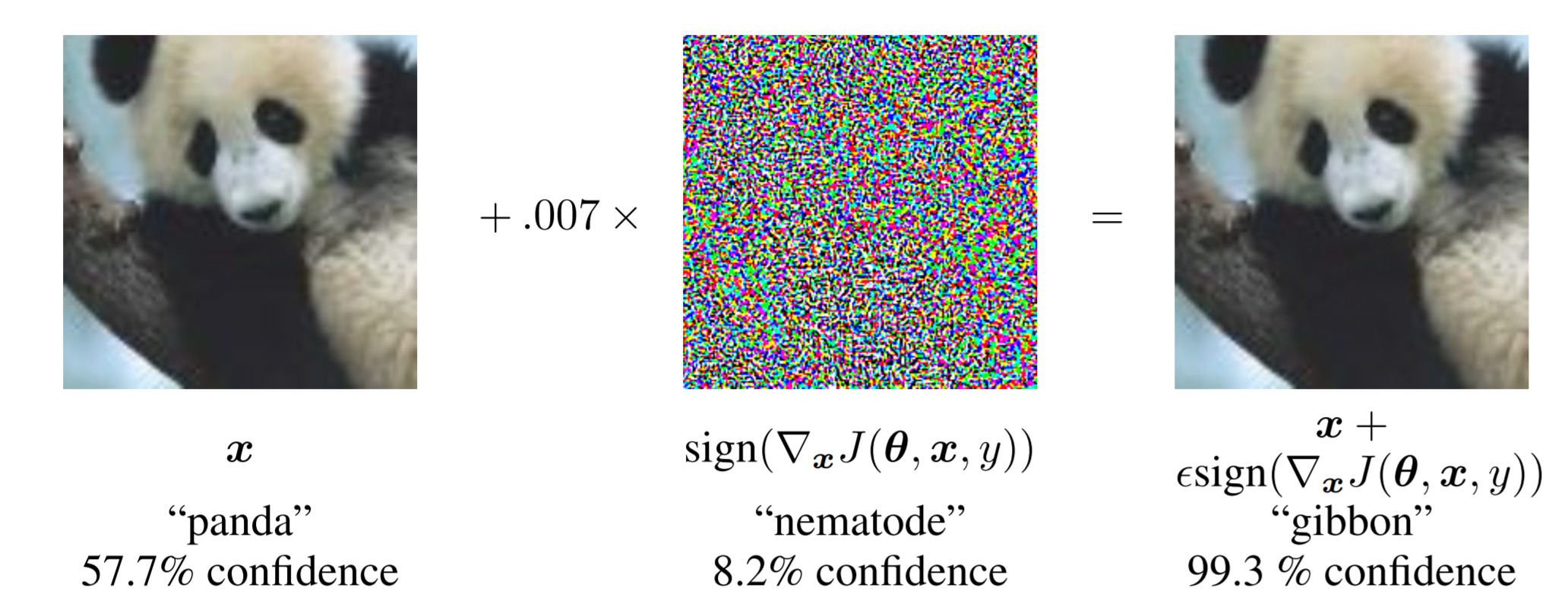
Source: Explaining and Harnessing Adversarial Examples (Ian J. Goodfellow, Jonathon Shlens, Christian Szegedy)
In the above image, the classifier interprets the first picture with 0.577 confidence as being a panda. When the pixel array in the middle (which alone is classified as having 0.082 confidence in being a nematode) is added to it, the image becomes classified with 0.993 confidence as a gibbon. To the human eye however, the image on the right still looks like a panda. This is where the main risk from adversarial examples comes from: the resultant image looks fine to the human eye, but causes a misclassification in the computer system. This makes them harder to detect. As for why panda+nematode=gibbon, I couldn’t tell you. Image classifiers are just a bit weird sometimes. If you would like to see more examples of weird classifier nuances, I would recommend this blog: http://aiweirdness.com/
So, can this be used for fooling facial detection/recognition systems? In a way, yes. If you had a backpropagation result of a human face, you could then subtract this value from the image of a face to cause the system to be less likely to classify it as a face. Alternatively, you could add the result of something else (such as a chair) to the image to usurp “human face” as the top classification. On the facial recognition front you could add the backpropagation of someone else’s face to try and appear as them, or subtract the backpropagation of yourself to reduce the chance of being identified as yourself.
This technique, in my mind, is not too useful in the real world. It can be used reliably to fool classifiers that exist solely within the digital domain, but not so much in the real world. If you didn’t want Facebook to use facial recognition on your photo then this method should work fairly well, as you are directly feeding it a digital image. In the real world, adversarial examples are a bit less effective. The subtle changes which enable the resultant images to fly under the radar of human eyes need to be more pronounced to be picked up by whatever camera is being used to gather images in advance of classification. It can still work (a famous example is a 3D printed turtle which is classified as a rifle from a variety of angles: https://www.labsix.org/physical-objects-that-fool-neural-nets/), but it tends to be a lot more difficult. Plus, it relies on the target neural network not functioning too differently from the one used in the crafting.
Another issue stems from how to deliver these adversarial examples in the real world. Work has been undertaken to use adversarial examples to induce misclassifications in driverless cars. An example of this can be seen below:
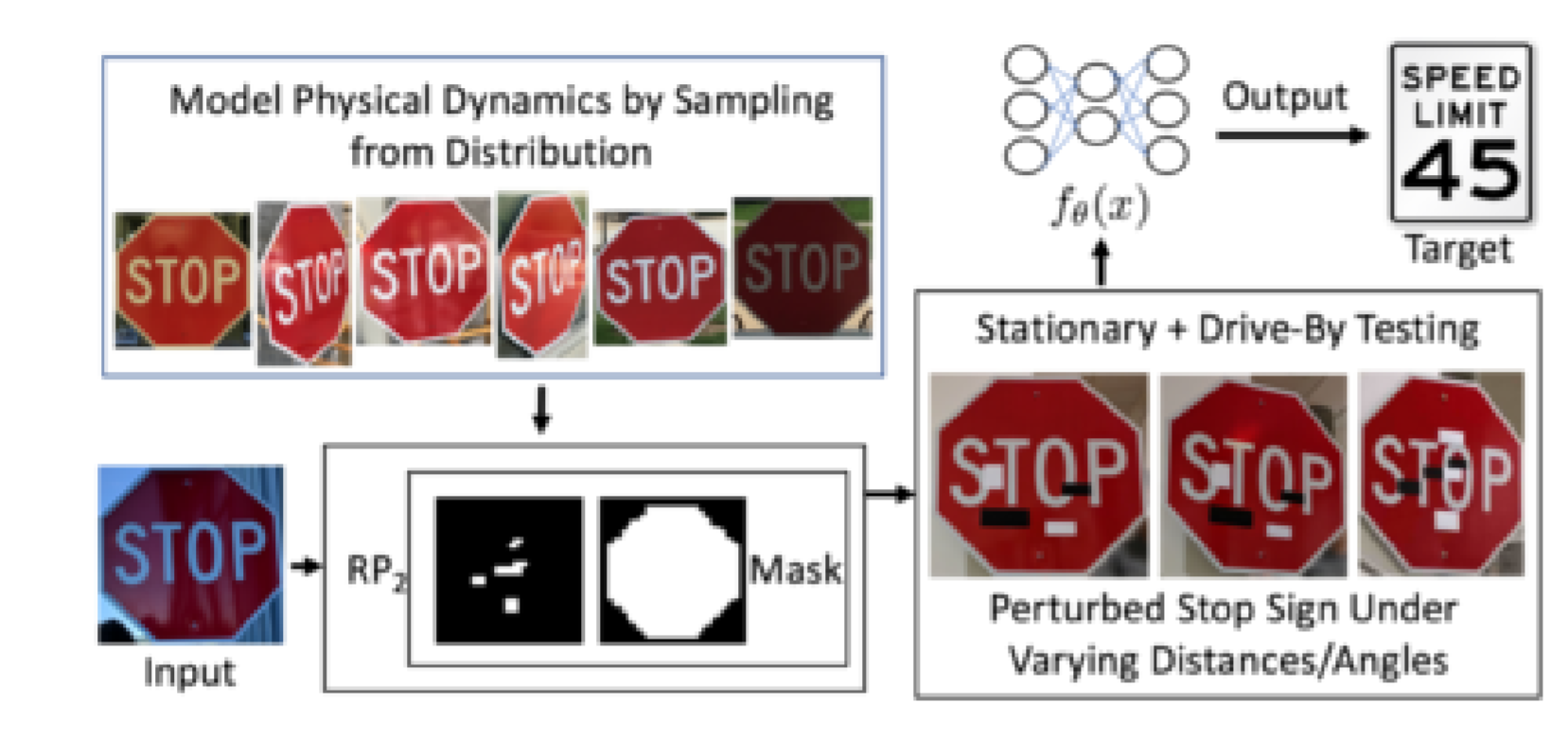
Source: Robust Physical-World Attacks on Deep Learning Visual Classification (Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, Dawn Song)
In this example, the stop sign is misclassified as a speed limit sign. The researchers made efforts to make their attack look like regular graffiti, so that humans won’t question it so much. Still, it does look obvious that the sign has been manipulated in some way; as knowledge of adversarial examples grows, the more people may begin to pay attention to such manipulations. This problem applies to fooling facial detection/recognition systems. How can we deliver the attack without it appearing obvious?
One proposed solution is through adversarial glasses, seen below:

Source: Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition (Mahmood Sharif, Sruti Bhagavatula, Lujo Bauer, Michael K. Reiter)
The weird colours of these frames are designed to in the case of column (a) above cause a system to no longer detect a human face, and in columns (b) to (d) cause the system to misclassify the face as the lower of the pair. Funky coloured glasses, although eye-catching, do not obviously appear out of place. One wouldn’t look at them and assume that the wearer is attempting to defeat a facial detection/recognition system. You would probably assume that they just like bright, quirky glasses frames. The ability to fly under the radar is, as previously mentioned, very important.
That said, I don’t think that these glasses work as well as they claim to. In the past I made a pair of them (as well as used images from the aforementioned report), and showed them to a neural network based facial detection system. It had zero issues with detecting the faces. I think that again this comes down to the ability to feed the carefully crafted manipulations in to the system whilst preserving as much of the permutations as possible. In the real world, the camera resolution might not match the one designed for in training. The lighting probably won’t be perfect, the angle won’t be correct. In driverless cars this is likely to be less of an issue as there is a lot more standardisation in viewing angle/hardware used, but for facial detection/recognition systems there’s quite a mix in use.
The area of adversarial examples for facial detection/classification is an interesting one, ripe for more work. At this point in time however I don’t think that it can be called a technique that can reliably be used in this domain. Perhaps one could knit an adversarial pattern in to a hat, or have it printed on a jumper to cause issues for a system. Perhaps subtle makeup could be used in this manner. I look forward to seeing what comes of it!
In my next post I’ll discuss other methodologies which can be used, perhaps more reliably.
[…] This article forms the third part of my discussion of the art community’s efforts to defeat facial detection/recognition techniques. If you haven’t read the first part (which describes how these systems generally work), it can be found here: https://www.vicharkness.co.uk/2019/01/20/the-art-of-defeating-facial-detection-systems-part-one/. The second part (which discusses adversarial examples for facial detection/recognition systems) can be found here: https://www.vicharkness.co.uk/2019/01/27/the-art-of-defeating-facial-detection-systems-part-two-adversar…. […]
[…] The art of defeating facial detection systems: Part two: The art community’s efforts – Vic Harkness on The art of defeating facial detection systems: Part two: Adversarial examples […]
[…] Part two: Adversarial examples: https://www.vicharkness.co.uk/2019/01/27/the-art-of-defeating-facial-detection-systems-part-two-adversar… Part three: The art community’s efforts to defeat these systems: […]